このノートは主に C++ における一般的な function と関連する知識点についてまとめたものです。
基本知識
C++ の function を使用するには、以下の 3 つの作業を完了する必要があります:
- function の定義(Definition)を提供する
- function の prototype(Prototype)を提供する
- function を呼び出す(Reference / Call)
function の定義
戻り値のない function は void function と呼ばれ、return がなくてもよいため、プロシージャやサブルーチンと呼ばれることもあります。戻り値のある function には必ず return が必要です。
C++void FunctionName (paramList) {
statements;
return; // optional
}
int FunctionNameAnother (paramList) {
statements;
return 0; // must return an int
}
引数リスト paramList では、各引数の型を明示する必要があります。
通常、function は戻り値を指定された CPU register や memory ユニットにコピーすることで値を返します。
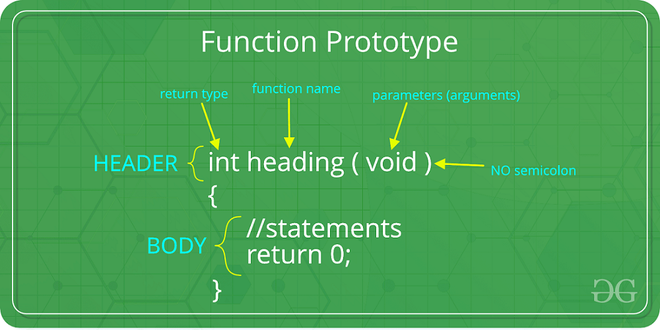
function prototype
C++ では function にその prototype を提供することが求められます。そのため、その理由と prototype の提供方法を理解する必要があります。
理由
prototype は、function の戻り値の型、引数の型および数を compiler に伝えます。compiler が function を使用するたびにファイル全体を検索するのは効率的ではありません。main() から離れる必要があるからです。また、function がファイル内に存在しない場合もあります。C++ ではプログラムを複数のファイルに分けて個別に compile し、後で組み合わせることが許可されています。この場合、main() を compile する際、compiler はそれらの function のコードにアクセスできない可能性があるため、function prototype によって情報を提供する必要があります。
syntax
基本的には、function 実装の中括弧部分をすべて削除し、セミコロンに置き換えるだけです。prototype では引数の名前は重要ではなく、省略することも可能です。
Plain Text// prototype
double Volume(int h, int w, int d);
// or double volume(int, int, int);
// definition
double Volume(int h, int w, int d) {
return h * w * d;
}
値渡し
C++ は通常、値渡し(Passed by values)を行います。これは function を呼び出す際、実際に渡されるのは実引数の「コピー」であり、元のデータそのものではないことを意味します。これにより、渡された引数自体が function 内のステートメントによって影響を受けることはありません。
その際、実引数(argument)と仮引数(parameter)は非常に重要な概念です:
- 実引数:function 呼び出し時に渡される具体的な値や変数を指します。呼び出し側で使用される実際のデータです。
- 仮引数:function 呼び出し時に function 名の後ろの括弧内に記述される、入力としての変数を指します。
例えば、
Plain Textvoid add(int x, int y) { // parameter x and y
int sum = x + y;
std::cout << "Sum:" << sum << std::endl;
}
int main() {
int a = 5;
int b = 10;
add(a,b); // arguments a and b
return 0;
}
値渡しの影響
- 性能:値渡しはコピーを作成します。大きなオブジェクトや構造体を渡す場合、コピーの作成と破棄によって高い性能オーバーヘッドが発生する可能性があります。
- データ安全性:値渡しの利点は、元のデータが function 内部の操作によって誤って変更されないことです。これにより、特定の状況下でコードの安全性と安定性が向上します。
参照渡し
値渡しとは異なり、参照渡し(Passed by References)は function の引数が渡された実引数の参照であることを意味します。function 内部での仮引数への変更は、実引数に直接影響します。
syntax 上では、型の後ろに & を付けることで参照渡しを表します。
Plain Textvoid modifyValue1(int &x) { x = 10; }
void modifyValue2(int x) { x = 10; }
int main() {
int a = 5;
int b = 5;
modifyValue1(a); // a is now 10
modifyValue2(b); // b is still 5
}
ポインタ渡し
ポインタ渡し(Passed by Pointers)は、function の引数として実引数のアドレスを渡すことを意味します。pointer を通じて、function は実引数の内容にアクセスし、変更することができます。
syntax 上では、型の前に * を付けることでポインタ渡しを表します。function を呼び出す際は、変数のアドレスを渡す必要があります。
Plain Textvoid modifyValue3(int *x) { *x = 10;}
int main() {
int a = 5;
modifyValue3(&a); // pass the address of a
// a is now 10
return 0;
}
function pointer
function pointer は C++ における特殊な pointer であり、function を指し示すことができ、それを通じて function を呼び出すことができます。function pointer の概念は、callback function の実装、動的な function 呼び出し、または引数としての function の受け渡しなど、特定のプログラミングシナリオで非常に有用です。
例えば、以下のような function があるとします。
Plain Textint add(int a, int b) {
return a + b;
}
この function を指す function pointer を定義するには、次のように記述します。
Plain Textint (*funcPtr)(int, int);
ここで、
- int は function の戻り値の型です。
- (funcPtr) は function pointer の名称であり、 はそれが pointer であることを示します。
- (int, int) は function の引数リストです。
function pointer の使用
function pointer を定義した後、function のアドレスを代入できます。
Plain TextfuncPtr = add;
または定義時に直接初期化します:
Plain Textint (*funcPtr)(int, int) = add;
その後、通常の function 呼び出しに似た syntax で function pointer を通じて function を呼び出すことができます:
Plain Textint result = funcPtr(2,3);
この例では、funcPtr(2,3) は実際には add(2,3) を呼び出しており、result の値は 5 になります。
活用シーン
- callback function:function pointer を別の function に引数として渡し、callback メカニズムを実現します。例えば、イベント駆動型プログラミングでは、イベント発生時に実行する callback function を function pointer で指定できます。
- 動的な function 呼び出し:状況に応じて呼び出す function を動的に選択できます。例えば、メニューオプションの選択をシミュレートする場合、function pointer を使用して異なる処理 function を呼び出すことができます。
- function 配列:似た機能を持つ function 群を格納する function pointer の配列を定義し、インデックスによって異なる function を呼び出すことができます。
注意:
- function pointer が指すのは code segment 内の function アドレスであり、データではありません。
- 通常の pointer と同様に、function pointer も null pointer になる可能性があるため、使用前に正しく初期化されていることを確認し、null pointer 呼び出しによるプログラムのクラッシュを避ける必要があります。
inline function
inline function は C++ の特殊な function です。主な目的は、function 呼び出しのオーバーヘッドを排除することでプログラムの実行効率を向上させることです。inline function は実装ファイル(.cpp ファイル)ではなく、header file(.h または .hpp)で定義される必要があり、本質的にはマシンコードの直接的な置き換えです。
C++ では、inline キーワードを使用して inline function を宣言できます。
Plain Textinline int add(int a, int b) {
return a + b;
}
この例では、add function が inline function として宣言されており、compiler は add function が呼び出されるたびに、add function のコードを呼び出し箇所に直接挿入しようとします。
inline function にはメリットとデメリットがあります。
メリット:
- 性能:inline function はマシンコードの直接的な置き換えであり、function 呼び出しのオーバーヘッドを回避します。単純で頻繁に呼び出される小さな function に適しています。
- compile 最適化:inline function のコードは呼び出し箇所のコンテキストとより密接に結合するため、より多くの最適化の機会を提供します。
デメリット:
- コードの肥大化:inline function が何度も呼び出されると、そのたびにコードが挿入されるため、最終的な実行ファイルのサイズが大きくなる可能性があります。特に function のサイズが大きい場合に顕著です。
- compiler の挙動が制御不能:inline キーワードを使用しても、compiler は状況(function が大きい、再帰呼び出しがあるなど)に応じて inline 化しないことを選択する場合があります。逆に、inline キーワードがなくても compiler が独自の判断で inline 化することもあります。
- デバッグの困難さ:inline function の展開により、デバッガで各 function 呼び出しを追跡することが単純ではなくなり、デバッグが困難になる場合があります。
header file と実装ファイル
前述の通り、inline function は実装ファイルではなく header file で定義する必要があります。header file と実装ファイルは C++ プログラミングにおいて異なる役割を担っており、本質的な違いはコードの組織化と用途にあります。これらを理解することは、C++ プログラムの記述と保守において極めて重要です。
header file は主にインターフェースの宣言に使用されます。これには function の宣言、クラスの定義、マクロ定義、定数定義、template 定義などが含まれます。header file には通常、具体的な実装詳細は含まれませんが、inline function は header file 内で実装を提供する必要があります。
実装ファイルには、function やクラスメソッドの具体的な実装が含まれます。実装ファイルは通常、1 つ以上の header file とペアになり、header file で宣言された function やメソッドを定義するために使用されます。header file は通常 #include 指令によって実装ファイルに取り込まれ、実装ファイルは compile ユニットの本体として compiler によってオブジェクトファイルに compile されます。
overload
function overload は C++ の重要な機能の一つであり、引数リストが異なる限り、同じスコープ内で同じ名前の複数の function を定義することを許可します。overload はコードの可読性と柔軟性を高め、同じ function 名で異なる入力引数に応じた異なる操作を実行できるようにします。
function の overload を成功させるには、以下の条件のいずれかを満たす必要があります:
- 引数の型が異なる:例えば、ある function は int を受け取り、別の function は float を受け取る。
- 引数の数が異なる:例えば、ある function は 2 つの引数を受け取り、別の function は 3 つの引数を受け取る。
- 引数の順序が異なる:引数の型が異なり、かつその順序が異なる場合も overload が可能です。
注意点:
- 戻り値の型は overload の判断基準に含まれません。戻り値の型だけが異なる 2 つの function がある場合、compiler はエラーを出力します。
- デフォルト引数を使用する場合、曖昧さを避けるよう注意が必要です。2 つの function の overload により compiler がどちらを呼び出すべきか判断できない場合、compile エラーが発生します。
Plain Textvoid display(int x, int y = 10);
void display(int x); // エラー:display(5) 呼び出し時に compiler がどちらを使用すべきか判断できない
- 2 つの overload function の引数リストが非常に近い場合、compiler が明確に選択できず、compile エラーが発生することがあります。
Plain Textvoid show(double d);
void show(float f);
show(5.0f); // 曖昧な呼び出し、compiler はどちらのバージョンを呼び出すべきか確信が持てない可能性がある
template
function template とは、汎用的な function を作成するための設計図または雛形を指し、異なる型の引数を受け取ることができます。template を使用すると、compiler は渡された実際の引数の型に基づいて、対応する function インスタンスを自動的に生成します。
template は template キーワードを使用して定義され、その後に template 引数リストが続きます。template 引数には通常 typename または class キーワードが使用されます。
Plain Texttemplate <typename T>
T add(T a, T b) {
return a + b;
}
これにより、他の場所でこの function を自動的に使用できるようになります。
Plain Textint main() {
int x = 5, y = 10;
double p = 3.14, q = 2.71;
cout << add(x,y) << endl; // int add(int, int)
cout << add(p,q) << endl; // double add(double, double)
return 0;
}
ここで T は template 引数であり、任意の型を表すことができます。compiler は add を呼び出す際に、渡された引数の型に基づいて対応する function インスタンスを生成します。ほとんどの場合、compiler は template 引数の型を自動的に推論できますが、必要に応じて明示的に指定することも可能です:
Plain Textcout << add<int>(5,10) << endl;
ただし、compiler が T の指す型を正しく推論できる必要があります。例えば add(3, 2.5) は、3 の時点で T を int と見なし、2.5 を処理する際に T が double であるべきだと判断するため、矛盾が生じて compile エラーになります。この問題を解決するには、template が複数の引数を受け取れるようにし、異なる template 引数を使用します:
Plain Texttemplate <typename T, typename U>
T multiply(T a, U b) {
return a * b;
}
int main () {
cout << multiply(5, 2.5) << endl;
}
特化
template の特化(Specialization)により、特定の型に対して特別な実装を提供できます。通常、特化は template の特定のインスタンスに対して異なる実装を提供することを指します。
例えば、完全特化(Full Specialization)は、template のすべての引数型に対して特定の実装を提供することを指します。
Plain Texttemplate<>
const char* add(const char* a, const char* b) {
return strcat(a, b);
}
この例では、add function は const char* 型に対して特化されたバージョンを提供し、文字列の結合に使用されます。
template のメリット
- コードの再利用:コードを一度記述すれば、型ごとに個別の function を記述することなく、複数の型で再利用できます。
- 型の安全性:従来の C マクロと比較して、template は型の安全性を提供し、異なる型間の変換時に発生する可能性のあるエラーを回避します。
- コードの簡素化:template を通じて、同様の機能を持つ異なる型のための複数の function 記述を避け、冗長性を減らすことができます。
template の局限性
- compile 時間の増加:template は compile 時にインスタンス化されるため、template の使用は compile 時間の増加を招きます。
- コードの肥大化:template はコードの肥大化を招く可能性があります。特に多くの異なる型でインスタンス化される場合、compiler は型ごとに個別のコードを生成し、それらは code segment に格納されます。
- デバッグの困難さ:template コードのエラーメッセージは複雑になることがあり、特に template のネストや型推論の失敗時にはデバッグが困難になる場合があります。
性能分析
function の memory 占有
変数
- 自動変数:function 内で宣言された変数はプライベートです。function が呼び出されると、これらの変数のために memory が割り当てられ、function 終了時に解放されます。
- 静的変数:function 内で static として宣言された変数の memory は、グローバル memory 領域(data segment または BSS segment)に割り当てられます。これにより、プログラムの全生存期間を通じて存在し続けます。
- 動的 memory 割り当て:function 内で new や malloc を使用して memory を割り当てると、heap 上に memory ブロックが割り当てられます。プログラマはこの memory を解放する責任があり、怠ると memory leak が発生します。必ずしも同じ function 内で解放する必要はありませんが、どの memory が割り当てられ、他の場所でどのように解放すべきかを把握しておく必要があります。
function pointer は本質的に code segment 内の特定の場所を指す pointer です。function pointer 自体が占有する memory は他の pointer と同じであり、システムアーキテクチャに応じて通常 4 byte または 8 byte です。function pointer が指す実際のコードは code segment(.text segment)に配置され、pointer 自体は宣言場所に応じて stack、heap、またはグローバル領域に格納されます。
function template
function template 自体は memory を占有しません。template が具体的な型の function としてインスタンス化されたときに初めて、対応するコードが生成されます。
複数の異なる型でのインスタンス化がある場合、各インスタンス化された function は独立した memory 空間を占有します。template は compile 時に実際のコードを生成するため、compiler は型ごとに個別の function コードを生成し、これらは code segment に格納されます。
function overload
function overload は本質的に、同じ名前で引数が異なる複数の独立した function を定義することです。各 overload function は独立しており、compiler はそれぞれに対して独立したコードを生成し、これらも code segment に格納されます。したがって、overload は複数の function インスタンス分の memory 空間を占有します。
function の再帰
再帰呼び出しのたびに、stack 上に新しい stack frame が割り当てられ、function のローカル変数と戻り先アドレスが格納されます。再帰の深度が深くなるほど、stack 上の memory 占有が増加します。再帰が深すぎると stack overflow を引き起こす可能性があります。