このドキュメントは、CMU 15-473/673 Visual Computing Systems コースの課題 1 に関するブログ兼ドキュメントです。この課題では、tile-based renderer のための sort-middle アルゴリズムの実装を行います。
Data Processing
SIMD
このプロジェクトでは、座標を渡すために Intel SIMD (Single Instruction Multiple Data) データ型を使用します。具体的には __m128 を使用します。これは Intel SIMD 命令セット固有のデータ型で、特に Streaming SIMD Extensions (SSE) 命令セットで使用されます。これは、4つの 32-bit 浮動小数点値を同時に格納および操作できる 128-bit レジスタを表します。
__m128 を処理するには、基本的な算術演算用の特定の API を使用する必要があります。この課題では、作業を完了するために特に以下の API が必要になります。
C++#include <xmmintrin.h>
int main () {
// Addition
__m128 result_addition = _mm_add_ps(1.0f, 2.0f);
__m128i result_addition_int = _mm_add_epi32(1,2);
// Subtraction
__m128 result_subtraction = _mm_sub_ps(1.0f, 2.0f);
__m128i result_subtraction_int = _mm_sub_epi32(1,2);
// Multiplication
__m128 result_mul = _mm_mul_ps(1.0f, 2.0f);
__m128i result_mul_int = _mm_mullo_epi32(1, 2);
// Division
__m128 result_div = _mm_div_ps(1.0f, 2.0f);
// Set to zero
__m128 zero = _mm_setzero_ps();
// Set to values
__m128 one = _mm_set_ps(1.0f, 2.0f, 3.0f, 4.0f);
}
また、比較演算やビット演算を処理するために SIMD 命令を使用することもできます。
C++#include <xmmintrin.h>
int main () {
// Equality comparison
__m128 result_equal = _mm_cmpeq_ps(1.0f, 1.0f);
__m128i result_equal_int = _mm_cmpeq_si128(1,1);
// Less than comparison
__m128 result_lessThan = _mm_cmplt_ps(1.0f, 2.0f);
__m128i result_lessThan_int = _mm_cmplt_si128(1,2);
// Greater than comparison
__m128 result_greaterThan = _mm_cmpgt_ps(1.0f, 2.0f);
__m128i result_greaterThan_int = _mm_cmpgt_si128(1,2);
// Bitwise AND
__m128 result_and = _mm_and_ps(1.0f, 2.0f);
__m128i result_and_int = _mm_and_si128(1,2);
// Bitwise OR
__m128 result_or = _mm_or_ps(1.0f, 2.0f);
__m128i result_or_int = _mm_or_si128(1,2);
}
N.4 Format
この課題では、vertex の位置は 4-bit の subpixel 精度を持つ固定小数点表現で格納されます。これは浮動小数点値の N.4 フォーマットと呼ばれ、n ビットが整数部、4 ビットが小数部を表します。
例えば、2進数表現の 1001.0110 は次のように理解できます。
- 整数部: 1001 = 9.
- 小数部: 0110 = 6/16 = 0.375
したがって、この数値は 9.375 です。
N.4 フォーマットは、浮動小数点の計算コストを削減するために GPU で広く使用されています。さらに、N.4 フォーマットにおいて最も重要な操作の 1 つは丸め処理です。この定義を用いると、N.4 フォーマットの浮動小数点数 a の 2 進数表現に対して、ビットシフトを使用して floor および ceil 操作を行うことができます。
Rasterization
Point-in-Triangle Test
シーンを rasterize する際、RasterizeTriangle() 関数を呼び出します。この関数は、出力画像の一領域と triangle を入力として受け取ります。そして、この画面領域内で、入力された triangle によって少なくとも部分的に覆われている可能性があるすべての 2×2 pixel ブロックを特定します。
このプロセスの中で、triangle が実際にこの 2×2 pixel ブロック内の sampling point を覆っているかどうかを判断する必要があります。これは triangle coverage test と呼ばれます。この部分は TestQuadFragment() 関数によって処理されます。この関数はこのブロック内の pixel に対応する 4 つの画面上の点の座標を入力として受け取ります。出力は、下の図に示すように、これらの点のうちどれが triangle の内部にあるかを示すビットマスクです。

__m128 レジスタは最大 4 つの整数を保持できるため、2 つのレジスタを使用して quad 2×2 fragment 内の 4 つの sampling point の x 座標と y 座標を格納します(コメントにある通り、N.4 固定小数点フォーマットです)。
Edge Equations
pixel が triangle に覆われているかどうかをテストするために、edge equation を使用します。triangle の 番目の vertex を とします。クエリ点 に対して、まず次を計算します。
番目の edge に対する edge equation は次のように計算されます。
点 が point-in-triangle テストに合格するための必要十分条件は次の通りです。
(E_0 > 0 \& E_1 >0 \& E_2>0) || (E_0 < 0 \& E_1 < 0 \& E_2 < 0).
つまり、edge equation が同じ符号を持つ必要があります。点がある edge の真上にある場合(すなわち )、その edge が現在の triangle に属しているかどうかを確認します。これは isOwnerEdge[i] にアクセスすることで確認できます。isOwnerEdge[i] が true であれば、その edge は triangle に属していることを意味するため、その edge 上のすべての点は triangle の内部にあるとみなします。
これで edge mask が明確になったはずです。
各 fragment のサンプルが覆われているかどうかを示すビットマスクを返す TestQuadFrag() 関数ができたので、triangle を rasterize することが可能になります。これは RasterizeTriangle() メソッド内で行います。triangle を rasterize する方法は次のように要約できます。すべての候補 pixel を見つけ、作成済みの TestQuadFrag() を使用して各 pixel の coverage をテストします。以下の入力を受け取ります。
regionX0,regionY0: 現在処理中の tile の左上座標。regionW,regionH: 現在処理中の tile の pixel 単位の幅と高さ。tri: triangle の方程式を設定します。triangle の vertex 座標を保存します。triSIMD: SIMD レジスタ内の tri のすべての値。processQuadFragmentFunc(): 関数値。coverage が発生する可能性のある各 quad fragment に対して、このメソッドはこの関数を呼び出す必要があります。
Finding the Bounding Box
候補を見逃すことなくテストを高速化するために、まず triangle の bounding box を見つけて、どの座標を調べるかを決定します。セクション 2.2 で説明した N.4 フォーマット浮動小数点数用のビット演算を使用することで、これを簡単に行うことができます。
Iterating Through All Quad Fragments
これで、単純に for ループを適用することで、triangle に覆われている可能性のあるすべての fragment を反復処理し始めることができます。各 quad fragment に対して、pixel 座標(左下、右下、左上、右上)をレジスタに保存します。次に、TestQuadFragment() メソッドを呼び出して、この triangle が受け入れられるかどうかを確認します。すべての quad がテストに合格する必要があるという単純な受け入れ条件を使用します。
Sort-middle Tile-Based Renderer
ここから、sort-middle 方式の tile-parallel renderer の実装を開始します。この tile renderer には 2 つのステージがあります。
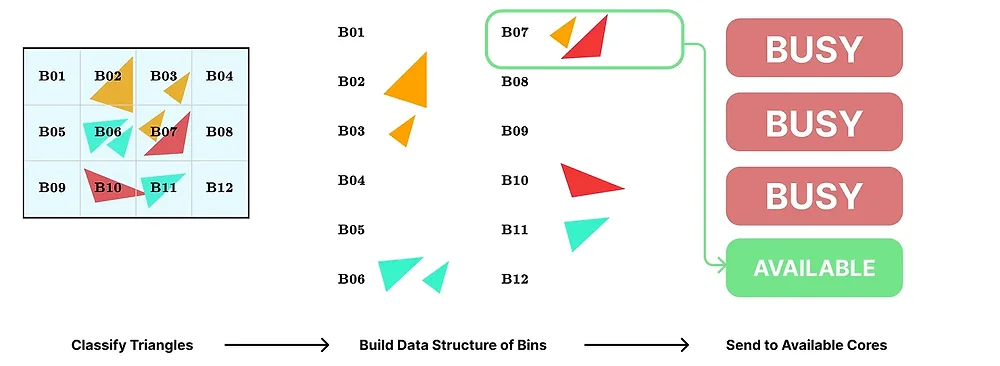
- triangle を bin に入れる。各画面 tile が bin を持ち、各 bin にはその tile と重なる可能性のある triangle のリストが含まれるデータ構造を構築します。
- bin を並列に処理し、次に利用可能なコアに未処理の bin を動的に割り当てます。
プロセスを図 2 に示します。
 図 2: Sort-Middle tile 並列化スキーム。各ステージを図に簡潔に示しています。
図 2: Sort-Middle tile 並列化スキーム。各ステージを図に簡潔に示しています。
Initialization
tile-based rendering では、画面を小さな tile に分割し、これを bin と呼びます。各 tile は、その内部にある triangle の処理を担当します。通常、パフォーマンスを向上させるために、triangle が覆う tile ごとに triangle を分類します。このプロセスは binning と呼ばれます。
bin を追跡する直感的な方法は、tile の vector を使用することです。ここで各 tile は投影された triangle(これを bin と呼びます)の vector です。しかし、マルチスレッド環境で binning を処理する場合、複数のスレッドが同時に triangle を処理し、対応する bin に入れる可能性があります。グローバルな bin に直接書き込むと、以下のような問題が発生する可能性があります。
- Race condition。複数のスレッドが同じデータ構造に書き込むことで、データの不整合やプログラムのクラッシュにつながる可能性があります。
- パフォーマンスのボトルネック。Race condition を避けるために、スレッドセーフを確保するためのロックを適用する必要がありますが、これは並列性を低下させるため、ほぼ確実に低速になります。
Thread-Local Bins
上記の問題を解決するために、threadLocalBins と呼ぶデータ構造で管理される thread-local bin を導入します。これにより、各スレッドは bin を管理するための独自の独立したデータ構造を持つことになります。スレッド i が binning を実行するとき、自身の threadLocalBins[i] にデータを書き込みます。thread-local bin を使用することで、ロックの使用も回避でき、同期コストを削減できます。各スレッドが自身の binning を完了したら、全員の local bin をグローバルな bin にマージし、処理のために ProcessBins() に渡す必要があります。
Steps
以下の手順は、BinTriangles() で完了させる必要のある作業を説明しています。
- 初期化。画面が
gridWidth×gridHeight個の tile に分割されていると仮定します。グローバル bin: これはgridWidth×gridHeightのサイズを持つ ProjectedTriangles の vector の vector になります。Thread-local bin: これは、すべてのスレッドのすべての local bin 構造を追跡するため、ProjectedTriangles の vector の vector の vector になります。つまり、threadLocalBins[threadId]はthreadId番目のスレッドの local bin を返します。 - Thread-local binning。各スレッドはシーン内の triangle の一部のみを処理します。各スレッドは自身の triangle coverage に基づいて、triangle を
threadLocalBins[threadId]に入れます。これは、単一のスレッドが 1 つまたは数個の tile のみを処理するため、threadLocalBins[threadId]内のほとんどの bin が空になることも意味することに注意してください。各スレッドにとって、自身の担当範囲外の tile は、図 3 に示すように空であるとみなすことができます。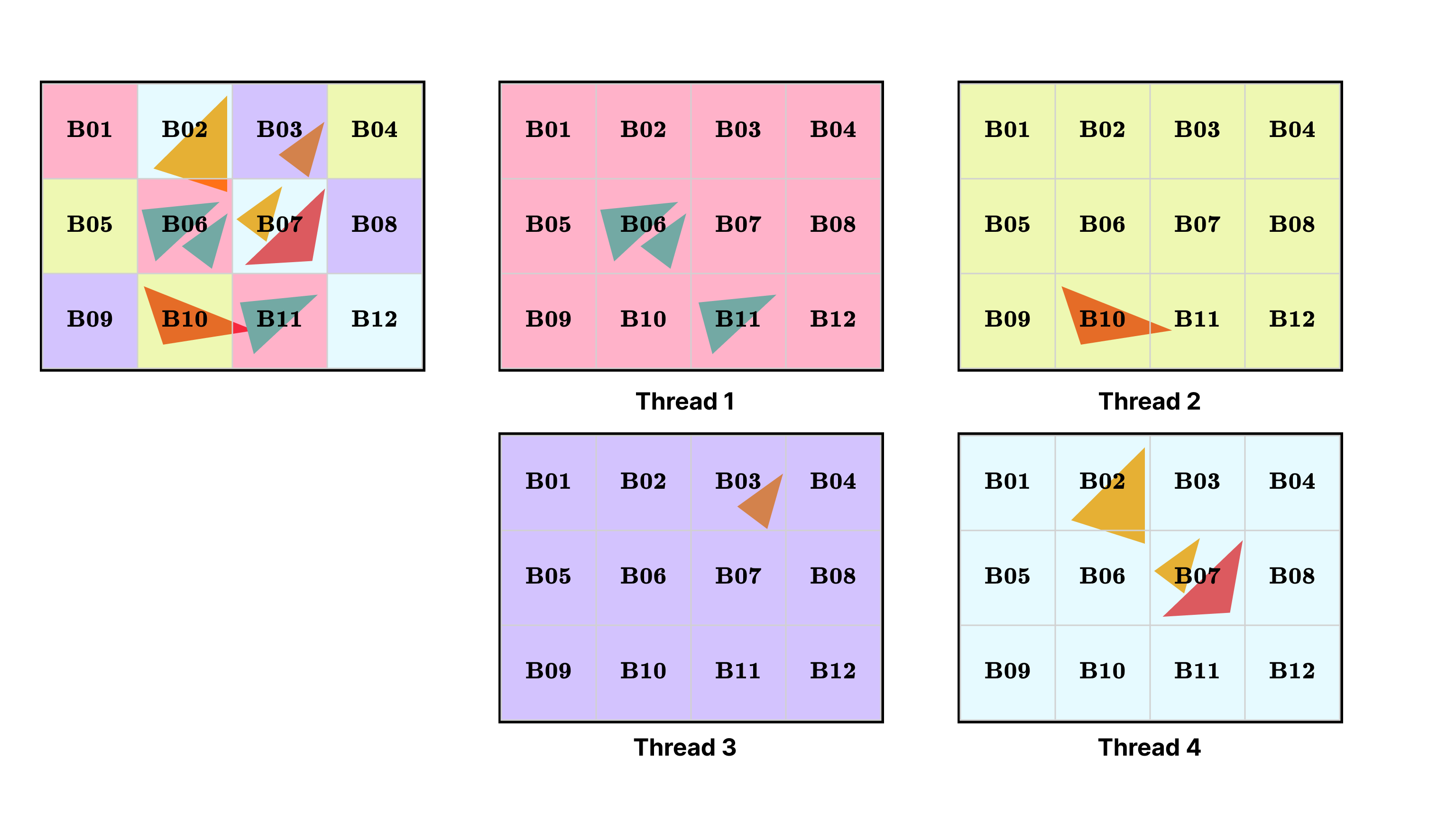
- グローバル bin へのマージ。すべてのスレッドが binning を完了した後、
threadLocalBinsからすべての local bin をグローバル bin にマージします。ここでは triangle が tile ごとにソートされています。各 tile に対して、すべてのスレッドからの triangle サブリストをマージします。これらのサブリスト内では、triangle はこの tile 内に位置しています。 - グローバル bin の処理。最後に、グローバル bin を反復処理し、tile 内の各 triangle を処理します。各 tile は独立して処理されるため、複数のスレッドで
ProcessBin()を実行します。
図 3: Thread-local bin。図の 4 スレッド renderer は 12 個の bin を処理しています。各スレッドは、シーン内の triangle の一部のみを処理する thread-local bin 構造を持っています。
Binning Triangles
次に行うのは、グローバル bin 内の bin を処理することです。各 tile に対して、ProcessBin() を呼び出して bin 内の fragment を rasterize します。tile-based renderer では、並列化は fragment 間ではなく tile 間で発生することに注意してください。tile 内の処理は逐次的です。したがって、非タイル型の実装のように完全な fragment buffer に対して ShadeFragments() を呼び出すのではなく、単一の quad fragment を shade するために ShadeFragment() を 1 回呼び出します。
Framebuffer Tiles
framebuffer に直接書き込む代わりに、color と depth を framebuffer に更新します。tile-based renderer の利点の 1 つは、framebuffer tile 全体がキャッシュに収まることです。最適なパフォーマンスを得るために、tile の処理中に結果を tile-major な framebuffer 構造に書き込み、最後に結果を renderer の framebuffer にコピーして戻します。
Adaptation
rasterization は quad fragment の粒度で行われるため、ループは tile 内の triangle を巡回し、4 つの fragment のそれぞれを反復処理します。セクション 3.2 で作成した RasterizeTriangle() を呼び出し、領域サイズとして現在の tile の sub-framebuffer サイズを指定します。
以下は、対処が必要になる可能性のあるいくつかの技術的課題です。
- fragment を直接 shade するため(fragment buffer 内で shade するのではなく)、
ShadeFragments()の代わりにShadeFragment()を呼び出します。ShadeFragment()のインターフェースを見ると、現在処理されている triangle をどのスレッドが処理しているかを知る必要があります。そうしないと、誤った vertex 出力 buffer や index 出力 buffer を使用してしまいます。 - tile 化された framebuffer に書き込んでいるため、index を慎重に扱う必要があります。
- 具体的には、
ShadeFragment()インターフェースに triId パラメータがありますが、これは ProjectedTriangle クラスのメンバ変数ではありません。これは、BinTriangles()でこの triangle を binning していたときのループの index です。
これらの問題を解決するために、この情報を保持して伝播させる必要があります。扱いやすくするために、スレッド ID、ループ index、および投影された triangle を保持する BinnedTriangle 構造体の vector を維持します。
これで、bin 全体を処理できるようになります。
Completion
処理が完了したら、結果を framebuffer に書き戻す必要があります。