本文档是 CMU 15-473/673 视觉计算系统课程作业 1 的博客/文档。该作业涉及为分块渲染器(tile-based renderer)实现 sort-middle 算法。
数据处理
SIMD
在本项目中,我将使用 Intel SIMD(单指令多数据)数据类型来传递坐标,具体来说我们将使用 __m128。它是 Intel SIMD 指令集特有的数据类型,特别用于 Streaming SIMD Extensions (SSE) 指令系列。它代表一个 128 位寄存器,可以同时存储和操作四个 32 位浮点值。
为了处理 __m128,我们需要使用特定的 API 进行基本算术运算。在本次作业中,我们特别需要以下 API 来完成工作。
C++#include <xmmintrin.h>
int main () {
// Addition
__m128 result_addition = _mm_add_ps(1.0f, 2.0f);
__m128i result_addition_int = _mm_add_epi32(1,2);
// Subtraction
__m128 result_subtraction = _mm_sub_ps(1.0f, 2.0f);
__m128i result_subtraction_int = _mm_sub_epi32(1,2);
// Multiplication
__m128 result_mul = _mm_mul_ps(1.0f, 2.0f);
__m128i result_mul_int = _mm_mullo_epi32(1, 2);
// Division
__m128 result_div = _mm_div_ps(1.0f, 2.0f);
// Set to zero
__m128 zero = _mm_setzero_ps();
// Set to values
__m128 one = _mm_set_ps(1.0f, 2.0f, 3.0f, 4.0f);
}
我们还可以使用 SIMD 指令来处理比较和位运算。
C++#include <xmmintrin.h>
int main () {
// Equality comparison
__m128 result_equal = _mm_cmpeq_ps(1.0f, 1.0f);
__m128i result_equal_int = _mm_cmpeq_si128(1,1);
// Less than comparison
__m128 result_lessThan = _mm_cmplt_ps(1.0f, 2.0f);
__m128i result_lessThan_int = _mm_cmplt_si128(1,2);
// Greater than comparison
__m128 result_greaterThan = _mm_cmpgt_ps(1.0f, 2.0f);
__m128i result_greaterThan_int = _mm_cmpgt_si128(1,2);
// Bitwise AND
__m128 result_and = _mm_and_ps(1.0f, 2.0f);
__m128i result_and_int = _mm_and_si128(1,2);
// Bitwise OR
__m128 result_or = _mm_or_ps(1.0f, 2.0f);
__m128i result_or_int = _mm_or_si128(1,2);
}
N.4 格式
在本次作业中,顶点位置将以具有 4 位子像素精度的定点表示形式存储,这被称为浮点值的 N.4 格式——n 位用于整数部分,4 位用于小数部分。
例如,二进制表达式 1001.0110 可以理解为:
- 整数部分:1001 = 9。
- 小数部分:0110 = 6/16 = 0.375
所以这个数是 9.375。
N.4 格式广泛用于 GPU 以降低浮点计算成本。此外,N.4 格式最重要的操作之一是舍入。使用这个定义,对于 N.4 格式浮点数 a 的二进制表示,我们可以使用位移来执行 floor 和 ceil 操作。
光栅化
点在三角形内测试
当我们想要光栅化场景时,我们将调用 RasterizeTriangle() 函数。该函数接收输出图像的一个区域和一个三角形作为输入。然后,它会识别该屏幕区域内可能至少部分被该输入三角形覆盖的所有 2×2 像素块。
在此过程中,我们需要确定三角形是否实际覆盖了该 2×2 像素块中的采样点——这被称为三角形覆盖测试。这部分由 TestQuadFragment() 函数处理——它接收四个屏幕点的坐标作为输入,对应于该块中的像素。其输出是一个位掩码(bitmask),指示这些点中哪些在三角形内部,如下图所示。
 由于一个
由于一个 __m128 寄存器最多可以容纳 4 个整数,我们将使用两个寄存器来存储 quad 2×2 fragment 中四个采样点的 x 和 y 坐标(采用注释中描述的 N.4 定点格式)。
边缘方程
为了测试像素是否被三角形覆盖,我们使用边缘方程。将三角形的第 个顶点标记为 。对于查询点 ,我们首先计算
第 条边的边缘方程计算如下
点 通过点在三角形内测试的充分必要条件是
(E_0 > 0 \& E_1 >0 \& E_2>0) || (E_0 < 0 \& E_1 < 0 \& E_2 < 0).
也就是说,边缘方程必须具有相同的符号。如果一个点正好落在边缘上(即 ),我们会检查该边缘是否属于当前三角形。我们可以通过访问 isOwnerEdge[i] 来检查这一点。如果 isOwnerEdge[i] 为 true,则表示该边缘属于该三角形,因此我们认为该边缘上的所有点都在三角形内部。
现在,边缘掩码应该很清楚了。
现在我们有了 TestQuadFrag() 函数,它返回一个指示每个 fragment 样本是否被覆盖的位掩码,我们将能够光栅化三角形。我们将在 RasterizeTriangle() 方法中执行此操作。我们光栅化三角形的方式可以总结为:找到所有候选像素,并使用我们已经编写的 TestQuadFrag() 测试每个像素的覆盖情况。我们将接收以下输入
regionX0,regionY0: 当前工作 tile 的左上角坐标。regionW,regionH: 当前工作 tile 的像素宽度和高度。tri: 设置三角形方程;我们保存三角形顶点的坐标。triSIMD: SIMD 寄存器中 tri 的所有值。processQuadFragmentFunc(): 一个函数值——对于每个可能产生覆盖的 quad fragment,此方法都应调用此函数。
寻找包围盒
为了在不遗漏任何可能候选者的情况下加快测试速度,我们首先找到三角形的包围盒(bounding box),以决定要查看哪些坐标。通过使用第 2.2 节中讨论的 N.4 格式浮点数的位运算,我们将能够轻松完成此操作。
遍历所有 Quad Fragments
现在我们可以开始通过简单的 for 循环遍历三角形覆盖的所有可能 fragment。对于我们查看的每个 quad fragment,我们将像素坐标(左下、右下、左上、右上)保存到寄存器中。然后,我们将调用 TestQuadFragment() 方法来查看该三角形是否被接受。我们将使用一个简单的接受条件,即所有 quad 必须通过测试。
Sort-middle 分块渲染器
现在我们将开始实现 sort-middle 分块并行渲染器。分块渲染器将有两个阶段:
- 将三角形放入 bin 中。它将构建一个数据结构,其中每个屏幕 tile 都有一个 bin,每个 bin 包含可能与该 tile 重叠的三角形列表。
- 并行处理 bin,动态地将下一个未处理的 bin 分配给下一个可用的核心。
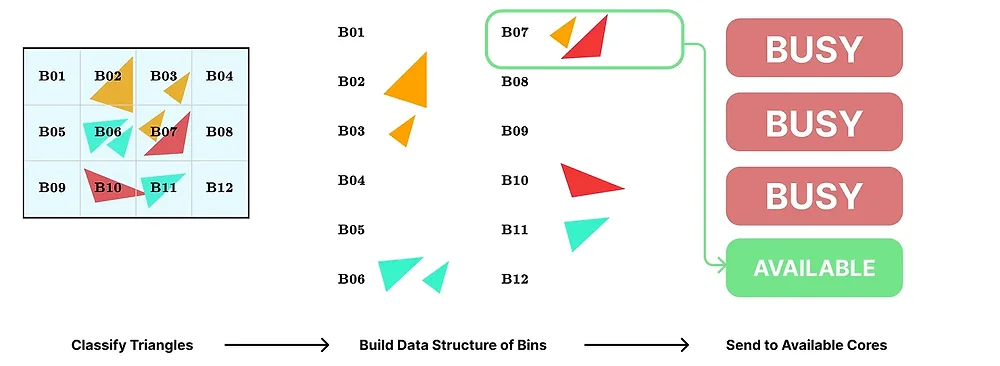
过程如图 2 所示。
 图 2:Sort-Middle 分块并行化方案。图中简要显示了各个阶段。
图 2:Sort-Middle 分块并行化方案。图中简要显示了各个阶段。
初始化
在分块渲染中,我们将屏幕划分为较小的块(tile),我们称之为 bin。每个 tile 将负责处理其中的三角形。通常,为了提高性能,我们将根据三角形覆盖的 tile 对其进行分类。这个过程被称为分箱(binning)。
跟踪 bin 的一种直观方法是使用 tile 向量,其中每个 tile 都是投影三角形的向量,我们称之为 bin。然而,当在多线程上下文中处理分箱时,多个线程可能会同时处理三角形并将其放入相应的 bin 中。如果它们直接写入全局 bin,可能会导致:
- 竞态条件。多个线程写入同一个数据结构——可能导致数据不一致甚至程序崩溃。
- 性能瓶颈。为了避免竞态条件,我们需要应用锁来确保线程安全——但这几乎肯定会很慢,因为它降低了并行性。
线程局部 Bin
为了解决上述问题,我们引入了线程局部 bin(thread-local bins),由我们称为 threadLocalBins 的数据结构维护。现在,每个线程都有自己独立的数据结构来维护 bin。当线程 i 执行分箱时,它将数据写入自己的 threadLocalBins[i]。通过使用线程局部 bin,我们还避免了使用锁,从而降低了同步成本。一旦每个线程完成自己的分箱,我们需要将每个人的局部 bin 合并到全局 bin 中,并交给 ProcessBins() 进行处理。
步骤
以下步骤描述了我们在 BinTriangles() 中需要完成的工作。
- 初始化。假设屏幕被划分为
gridWidth×gridHeight个 tile。全局 bin:它将是一个 ProjectedTriangles 的向量的向量,大小为gridWidth×gridHeight。线程局部 bin:它将是一个向量的向量的向量,因为它将跟踪所有线程的所有局部 bin 结构。也就是说,threadLocalBins[threadId]返回第threadId个线程的局部 bin。 - 线程局部分箱。每个线程将只处理场景中一部分三角形。它们将根据自己的三角形覆盖范围将三角形放入
threadLocalBins[threadId]。请注意,这也表明threadLocalBins[threadId]中的大多数 bin 将是空的,因为单个线程只会处理一个或几个 tile。对于每个线程,其职责范围之外的 tile 可以被视为空,如图 3 所示。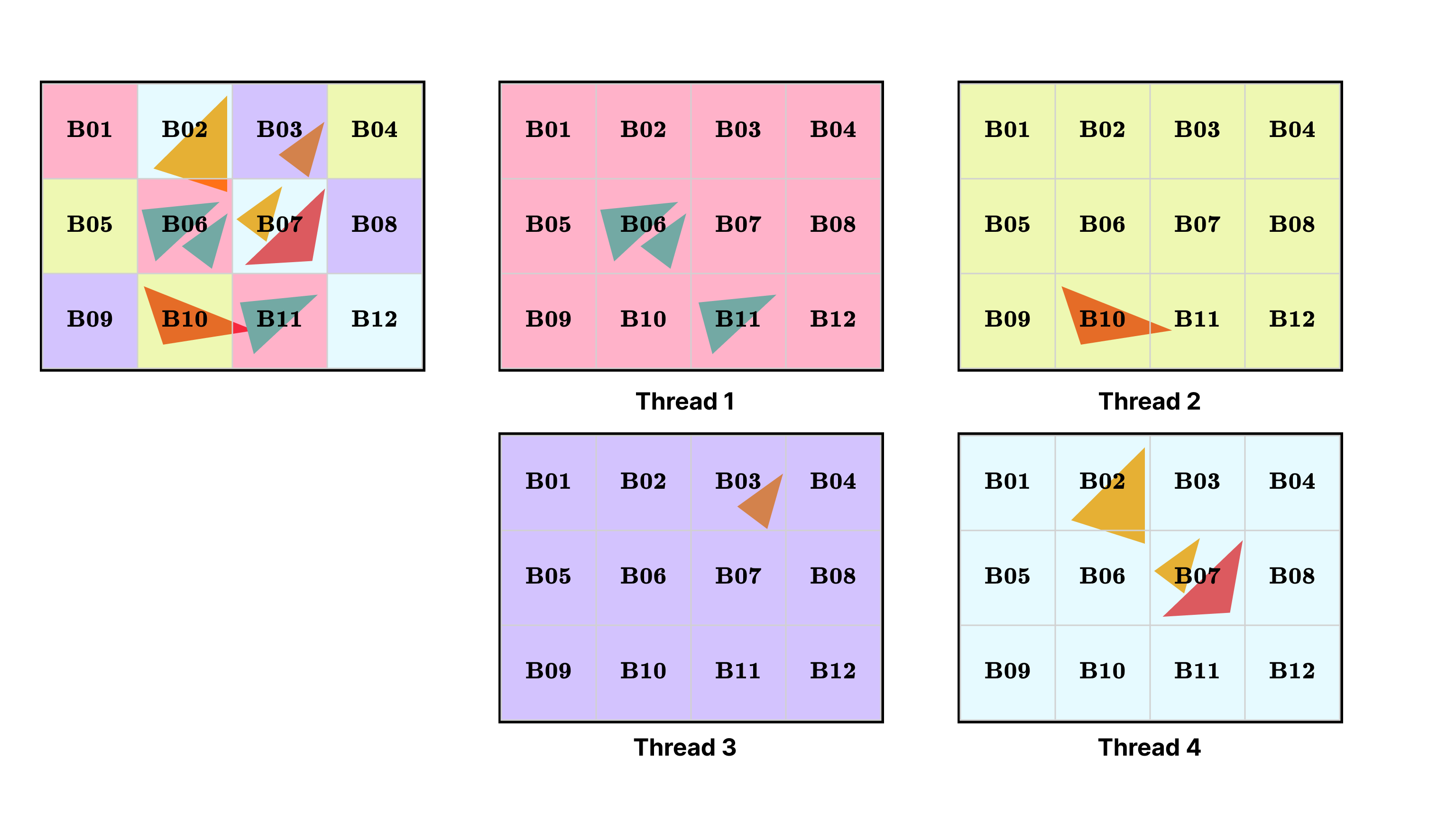
- 合并到全局 bin。在所有线程完成分箱后,我们将
threadLocalBins中的所有局部 bin 合并到全局 bin 中,其中三角形按 tile 排序。对于每个 tile,我们合并来自所有线程的三角形子列表。在这些子列表中,三角形位于该 tile 内。 - 处理全局 bin。最后,我们遍历全局 bin 并处理 tile 中的每个三角形。由于每个 tile 是独立处理的,我们将在多个线程上运行
ProcessBin()。
图 3:线程局部 bin。图中的 4 线程渲染器正在处理 12 个 bin。对于每个线程,它都有一个线程局部 bin 结构,仅处理场景中的一部分三角形。
三角形分箱
我们接下来的工作是处理全局 bin 中的 bin。对于每个 tile,我们将调用 ProcessBin() 来光栅化 bin 中的 fragment。请注意,在分块渲染器中,并行发生在 tile 之间,而不是 fragment 之间。tile 内部的处理是顺序执行的。因此,我们将调用一次 ShadeFragment() 来着色单个 quad fragment,而不是像非分块实现中那样在完整的 fragment buffer 上调用 ShadeFragments()。
帧缓冲块
我们不是直接写入帧缓冲(framebuffer),而是将颜色和深度更新到帧缓冲。分块渲染器的一个优点是整个帧缓冲块(framebuffer tile)都可以放入缓存中。为了获得最佳性能,我们将在处理 tile 时将结果写入 tile-major 帧缓冲结构,然后在最后将结果复制回渲染器的帧缓冲。
适配
由于光栅化是在 quad fragment 的粒度上进行的,循环会遍历 tile 中的三角形并迭代四个 fragment 中的每一个。我们将调用我们在第 3.2 节中编写的 RasterizeTriangle(),并将区域大小指定为当前 tile 的子帧缓冲大小。
以下是我们可能需要解决的一些技术挑战:
- 由于我们直接着色 fragment(而不是在 fragment buffer 中着色 fragment),我们将调用
ShadeFragment()而不是ShadeFragments()。查看ShadeFragment()的接口,我们需要知道哪个线程正在处理当前处理的三角形。否则,我们将使用错误的顶点输出缓冲区或索引输出缓冲区。 - 由于我们正在写入分块帧缓冲,我们需要仔细处理索引。
- 具体来说,
ShadeFragment()接口中有一个 triId 参数——这不是 ProjectedTriangle 类的成员变量。这是我们在BinTriangles()中对该三角形进行分箱时的循环索引。
为了解决这些问题,我们需要携带并传播这些信息。为了便于处理,我们将维护一个 BinnedTriangle 结构体向量,其中结构体持有线程 ID、循环索引和投影三角形。
现在我们将能够处理整个 bin。
完成
处理完成后,我们需要将结果写回帧缓冲。